 公式資料
公式資料
「デジタルオペレーションの現状」独自調査レポート
エンジニアの燃え尽きを防ぐ秘訣とは?
一段と信頼性の高いシステムを顧客が求めるようになり、勤務時間外や夜間の対応など、技術チームへの要求も増しています。本レポートでは、19,000 社以上、100 万人を超えるユーザーで構成されるPagerDutyプラットフォームから収集したデータを基にしたシステム運用の”今”を解説!→ PagerDutyの資料をみる(無料)


IT業界で働く人の中には、システム障害やインシデント対応にかかったコストを算出する際、「ダウンタイムの長さ」や「影響を受けた顧客と社員の人数」を中心に考慮する人が多くいるかもしれません。もちろん、こうした情報はニュースで大きく取り上げられるため、顧客の評判と信頼はビジネスの根幹に関わりますので正しい考え方です。一方で、システム障害やインシデントそのものに対応する人件費をコストとして考えることも重要です。「原因の調査、インシデントの解決、対応業務完了の判断」は、システム障害・インシデントの顧客への影響の大きさとは別の領域で発生する業務です。
PagerDutyのデータによれば、インシデント対応時間の50%は、サポートを強化する上で誰がベストメンバーなのかを判断すること(または、本当に問題があるのかの判断)に費やされています。つまり、インシデント対応時間の50%は修復作業ではなく初期段階(アラートやノイズの診断とトリアージの段階)に費やされていることといえます。つまり、「インシデントごとに発生する人の稼働時間」と「その作業数」がコスト増の大きな要因になる可能性があります。そして、こうしたコストを削減する方法として「インシデント対応の自動化」は有効な手段の一つといえます。
本記事では、「インシデント対応を自動化する重要性」や「自動化によって実現されること」、そして「MTTR(平均修復時間)の考え方」について解説します。インシデント対応コストの測り方や削減方法についてお悩みの方は、ぜひ参考にしてください。
目次
まず、「インシデント対応の自動化の重要性と診断データ」についてご紹介します。
インシデント発生時の初期段階における「深刻度診断」や「原因把握の自動化」を取り入れることは、インシデント修復を成功させる大きな鍵です。インシデントが発生するたびに発生する繰り返し作業によるエンジニアの疲弊からチームを守るという点で、自動化は人間にとっても重要です。アラート診断データを初期対応者に提供することこそが、ルーティン作業の効率化とインシデント対応ワークフローの最適化に欠かせません。アラート・ノイズ診断を自動化すれば、インシデントの発生時間と対応者の人数が減り、インシデントコストの削減につながるでしょう。
続いて、「アラート診断データ」について。「アラート診断データ」とは、インシデント対応者が取得するデータのことで、通常は監視ツールから提供される情報よりも具体的です。例えば、監視ツールが「CPUの使用率」や「メモリ使用量の急上昇」時にアラートを出すのに対し、インシデント対応者はCPUとメモリを最も多く消費しているプロセスを調べます。このプロセス名やID、コンピューターリソースの使用量が「アラート診断データ」といえます。
様々なITツールが発信するイベント情報からアラートを自動で収集、ノイズを除去したうえで、アラート診断データを初期対応者へ通知します。これにより、専門スタッフが小さな問題に煩わされる頻度をさらに削減します。
※エスカレーション……問題や課題が解決できない状況に直面した際に、上司や上位の管理者に報告・支援を求めること。
「過去の類似インシデント」や「直近の構成・コード変更」など、インシデントに関連が深いと思われるコンテキストを自動で提示します。チーム内外の情報連携も支援し、インシデントの迅速な解決を促します。
マルチクラウド環境などシステム構築環境が複雑化する現場では、インシデントの検知や対応に関しても複雑性や難易度が増しています。アラート診断の自動化はこのような環境下でも安全に実行され、サービス品質や安全性の維持が可能です。
※VPC……Virtual Private Cloud。クラウドコンピューティング環境における、仮想的なプライベートネットワークを指す。
定型的なインシデントなど、一部のケースに関しては、アラート診断・修復作業の自動化も可能です。人の判断を必要としない問題を自動で刈り取ることにより、迅速な解決とコスト削減につながります。
自動化によって、真に解決が必要な問題のみを吸い上げるため、新人エンジニアを効率的に育成できます。
「インシデントの検知、アラート診断から対応、情報共有」までを一貫して支援し、あらゆる関連組織の効率性を確保します。より少ないリソースで迅速に解決するだけでなく、将来のインシデントを未然に防ぐ効果も期待できます。
修復時間を考える際には「MTTR(平均修復時間: Mean Time To Repair)」が重要だと考えられていますが、PagerDuty では、「MTTT(平均トリアージ時間:Mean Time To Triage)」と「MTTI(平均調査時間:Mean Time To Investigate)」も重要であると考えています。
「MTTR(平均修復時間)」という指標は、インシデント対応体制を改善するために、細かい粒度で実用的なインサイトを得るには少し具体性を欠いています。MTTRはこの数十年間、IT業界の誰もが認める保全性の指標でした。様々な用途がある中でも修復率を測る指標として優れていますが、全体像しか示さない点に弱点があります。そこでPagerDutyは「対応時間の50%がサポートを強化する上で誰がベストメンバーなのかを判断することに費やされている」という前提から、「MTTT(平均トリアージ時間)」や「MTTI(平均調査時間)」といったMTTRタイムライン内の他の指標にも着目しました。
MTTI・MTTTとは、「インシデントの検知」から組織が「その原因と解決策の調査」を開始するまでの平均時間、つまり「MTTD(平均検知時間)」の終了から「MTTR(平均修復時間)」開始までの時間を指します。PagerDutyは、初期対応者がインシデントを確認した時点から、現場対応者に連絡が届くまでの時間を計測し、インシデント発生中に何が起きているのかを調べました。PagerDutyの自社データを分析した結果、「MTTRのうち最も時間がかかる要素の1つがMTTIだ」と推察できたのです。
MTTIが長くなる原因は、対応者がアラート診断データを手動で取得したり、サービスとインシデントによってどのチームにエスカレーションすべきかを判断したりといったテクニカルなものだけではありません。必要な専門知識を持った人的リソースの不足も原因になります。初期対応者によくあるのが、データベースとネットワーク観点を用いた方法を知らないケースです。これは、「スキル不足(データベースやネットワーク知識の欠如)、必要なアクセス権限、文書化されていない知識(サードパーティのサービスと複雑に統合されているアプリケーションなど、特定グループ内でのみ知られている知識等)」などに起因します。
このような作業を自動化し、さらにチームと対応者に任せることができれば、MTTIひいてはMTTRにプラスの連鎖的効果が期待できます。特に、「アラート診断自動化ツール」の活用は有効であり、MTTI短縮において大きな一手となるでしょう。属人化されたインシデント対応の一部をツールに任せることで、スムーズで最適化されたインシデント対応が実現可能です。
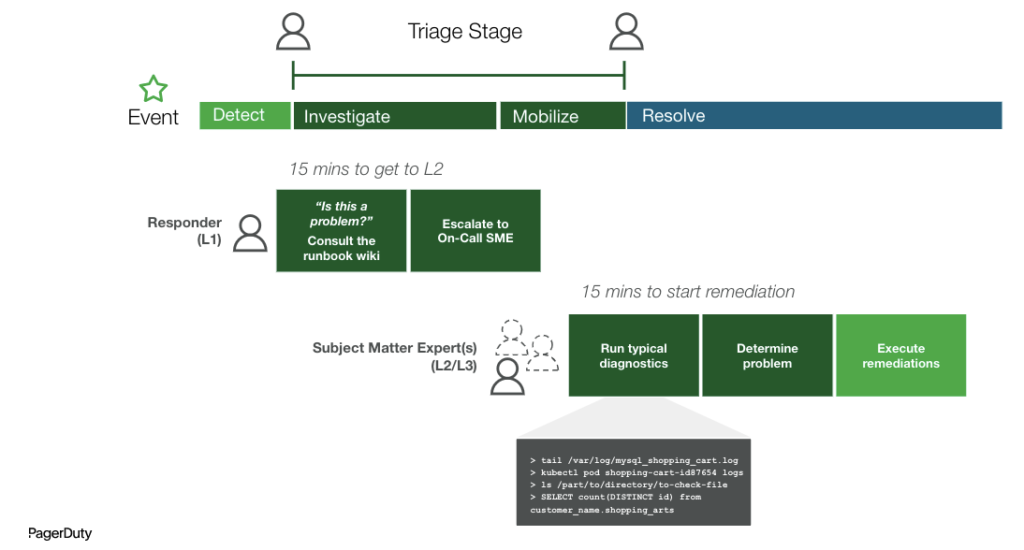
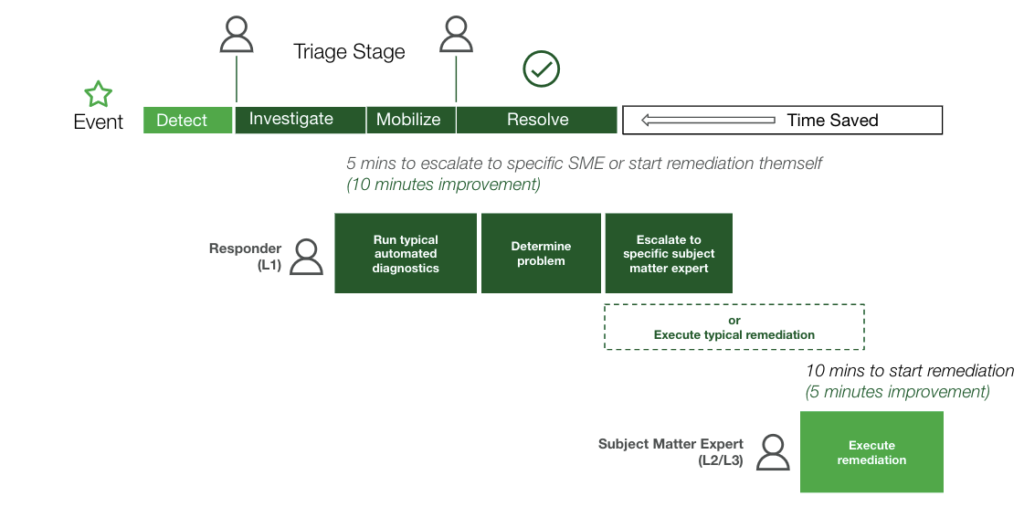
初めてインシデント対応の自動化を検討する場合、まずは「複雑さとリスクの低いタスク」から始めてみることをおすすめします。例えば、最もノイズの多いサービスを詳しく調べたり、さまざまな監視アプリケーションからディスク使用率などの簡単なデータを収集したりすることが考えられます。重要なのは、その場しのぎの対応を繰り返すのではなく、長期的な視野を持ち、戦略とビジョンをもとに自動化機能を展開することです。
「アラート診断の自動化」により、様々なITツールが混ざり合う動的な環境であっても「連動可能な、標準化されたアプローチの実現」をめざすことができます。ツールによってアラート診断の自動化ができると、作業時間はもちろん、教育リソースの削減など、組織レベルでの効率化を図れるのもポイントです。
PagerDutyでは、大量に発生するアラートのコンテキストをAIが分析し、80~99%ものノイズを除去することが可能です。「人が対応すべきインシデントだけ」を通知するため、担当者の負担は大幅に削減できます。また、アラートへの対処をルール化し、自動化による解決を試行することで、迅速なインシデント解決も支援します。運用担当者の負担を軽減し、素早く適切な対処が可能となるPagerDutyを、ぜひお試しください。
▼こちらの記事もおすすめ
> システム障害を未然に防ぐ「インシデント管理」とは?
> インシデント対応とは?事例から読み解く対策方法
エンジニアの燃え尽きを防ぐ秘訣とは?
一段と信頼性の高いシステムを顧客が求めるようになり、勤務時間外や夜間の対応など、技術チームへの要求も増しています。本レポートでは、19,000 社以上、100 万人を超えるユーザーで構成されるPagerDutyプラットフォームから収集したデータを基にしたシステム運用の”今”を解説!→ PagerDutyの資料をみる(無料)

この記事が気になったら




PageDuty公式アカウントをフォロー

PagerDuty
Manager, Solutions Consulting
ソリューションズコンサルティング マネージャー
PagerDuty
Manager, Solutions Consulting
ソリューションズコンサルティング マネージャー
ネットワーク機器メーカーにて、インターネット・データセンターのインフラ構築に従事した後、CDNベンダーにて主に動画・ゲーム・電子書籍サービスの拡張性ならびに信頼性向上・セキュリティ対策プロジェクトを推進。2022年よりPagerDuty株式会社にて、インシデント対応の自動化等、デジタルオペレーションのモダン化・成熟度向上を支援している。趣味は自家製スモーカーを使ったベーコン等の燻製作り。
SNS
 関連ブログ記事
関連ブログ記事
 人気記事
人気記事 検索
検索 タグ
タグ目次












