 を14日間無料で試してみる
を14日間無料で試してみる
700以上ものツールと連携。システム障害を自動的に検出・診断するだけでなく、適切な障害対応メンバーをアサインし、デジタル業務全体の修復ワークフローを自動化します。


現代の複雑なシステム運用では、故障や問題発生時の影響は大きく、重大なシステム障害やプロジェクトの遅延などをもたらしてしまいます。人の手によるインシデント対応ではMTTR(Mean Time To Recovery: 平均修復時間)がなかなか改善せず、サービスの質低下や従業員の負担増大を招く原因になっているかもしれません。
顧客が利用するサービスの質向上や従業員の負担軽減を推し進めるためには、「システム運用状態の可視性」や「効率性を高める取り組み」が必要になります。そこで役立つのが「PagerDuty Analytics」です。本記事では、MTTRの向上に向けて必要なことを解説します。併せて、MTTRに頼りすぎることなくインシデント改善を行なえるポイントについてもご紹介します。
目次
ここでは、MTTRの向上を目指す際に必要な要素を3つ解説します。
MTTR全般の向上を目指すなら、MTTR指標に頼りすぎてはいないか、依存度を見直しましょう。
インシデントが発生した際は、解決や修復に時間がかかるほど、顧客からの信頼度や企業の利益には深刻な影響が出てしまいます。
現在のMTTR指標だけに頼り過ぎていては、MTTR全般の向上には繋がりません。それどころか、システム障害による顧客への影響や従業員の負担などは増える一方でしょう。顧客からの信頼とMTTR全般の向上を目標とするならば、自動化およびデータ駆動型の実用的な洞察が必要不可欠です。
MTTRを向上させるには、まずより正確なMTTRを求める必要があります。MTTF(Mean Time To Failure: 平均故障時間)やMTBF(Mean Time Between Failures: 平均故障間隔)など、他の指標も使ってシステム障害を全体的に把握し、正確なMTTRを求めたうえで、向上へと動いていきましょう。
MTTR向上のためには「平均値」を信頼しすぎないことも大切です。
インシデント対応における平均値とは、インシデントの認知・修復・復旧・解決までの時間を表します。そもそもMTTRとは、インシデント発生時からシステムが正常に稼働するまでの「修復時間の平均」を表すものです。
しかし、インシデント対応における修復時間には、上限が存在しません。そのため、インシデントの継続時間が過剰に延びた場合、修復の平均値であるMTTRの数値も逸脱した値を表すことになってしまいます。
MTTRの向上を目指すなら、平均値の代わりに、歪曲分布・多極次数分布・百分位数などを使用してみましょう。数値そのものの全体像が明確になり、基準値からどれだけ離れているかが分かります。
エンジニア企業のように、複雑な環境で作業するチームにとって、MTTRは改善が難しい指標です。
なぜなら、MTTRはインシデント管理が未経験のチームのように、一次元的で変化の少ない環境でしか役に立たないことが多いためです。インシデント対応のワークフローの仕組みが確立されれば、MTTR以外にもさまざまな指標がないと、インシデントの発生時や対応時の全体像を正しく把握できなくなります。
MTTRだけに頼り続けていれば、同様のインシデント課題に何度も取り組むことになります。そこから、業務効率の悪化やエンジニアの負担増大、顧客からの信頼喪失、企業の業績悪化などの問題にも繋がりかねません。同様のインシデント課題に何度も取り組まなくて済むようにするには、インシデントから学び、それをサービスの信頼性向上に役立てていく必要があります。
また、顧客の使用パターンや新しいコード、機能など、サービスの環境を変化させる要素はほかにもたくさんあります。
複雑なシステムでインシデントが発生した際には、状況の把握に複数のチームとシステムが関与するため、場合によっては厄介なプロセスを踏まなくてはなりません。ある期間に発生したインシデントの復旧時間のみを比較しただけでは、そのサービスの稼働状況を正しく把握理解するのは不可能でしょう。そのため、MTTRの改善・向上に重要なのは、インシデントに対応する量ではなく、インシデントに関する十分な知識やその質です。
MTTRの向上を目指すなら、振り返りの会議では「インシデントが発生して対応するたびに討論を十分に行なうこと」が大切になります。
MTTRの向上を目指すには「MTTRに頼り過ぎないこと」が重要であると解説してきました。しかし、MTTRはエンジニアにとって引き続き重要な指標であり続けることには変わりありません。
PagerDutyを利用し始めたチームのなかには、詳細なインシデント管理プランを立てずとも、短期間でMTTRを劇的に改善できた例が多くあります。インシデント解決に大きく関わるのが、チームの招集・自動化の導入・コミュニケーションです。
この点でまだ十分に経験を積んでいない場合は、まず優れたツールを用意すると良いでしょう。データの蓄積方法の改善も、チームのMTTR短縮実現に向けた第一歩です。インシデント対応ワークフローを効果的に使えるようになったチームが、サービスのさらなる信頼性向上を目指す際に、MTTRだけを指標とするのには限界があります。たとえ2倍の数のインシデントに対応しても、データセットの量が増えなければ、MTTRはまったく変化しないか、したとしても多少変動するくらいです。それどころか、インシデントの数が増えれば、ユーザーは信頼性が落ちたという印象を持つでしょう。
MTTRの変化は、信頼度にそれほどの影響を与えません。平均値にこだわりすぎると「木を見て森を見ず」の状況に陥る恐れがあります。データに関してチームが重視すべき点は、インシデントに必ず優先順位をつけることです。
優先順位は、インシデントに自動で割り当てられる訳ではありません。チームによって、アラートデータをもとに優先順位を設定するケースや、インシデントの発生中に優先順位を手動で変更するケースなどがあります。その他、インシデントへの反映をより正確に行なうために、インシデント解決後に遡及的な優先順位の修正を行なうケースもあるなど、さまざまです。チームが対応すべきインシデントそれぞれに優先順位を割り当てることで、影響が最も大きいインシデントが発生した際に、チームの対応状況を把握できます。
また、優先順位をインサイトの表示画面でフィルターとして使えば、最優先すべきインシデントの把握が可能です。
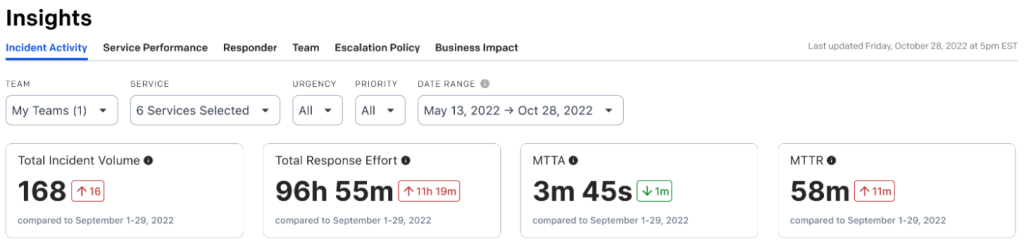
チームが短時間で解決できるような優先度「低」のインシデントを数多く担当していれば、優先順位の高いインシデントの存在を見過ごしてしまうでしょう。しかし、優先順位を割り当てる機能を使えば、インシデントのばらつきを調べ、顧客への影響が最も高いインシデントを優先できます。
インシデント対応ワークフローの新規導入時にMTTRを監視することは、チームのパフォーマンス改善の評価に役立ちます。しかし、MTTRの向上を目指すのであれば、その他の要素も取り入れていくことをおすすめします。そこで活躍するのが「PagerDuty Analytics」です。
PagerDuty Analyticsについての詳しい情報や最新機能については、PagerDutyの資料や無料トライアルをぜひご利用ください。
[ご参考] PagerDuty公式ダウンロード資料
https://www.pagerduty.co.jp/resources
700以上ものツールと連携。システム障害を自動的に検出・診断するだけでなく、適切な障害対応メンバーをアサインし、デジタル業務全体の修復ワークフローを自動化します。

この記事が気になったら




PageDuty公式アカウントをフォロー
 関連ブログ記事
関連ブログ記事
 人気記事
人気記事 検索
検索 タグ
タグ目次













