 公式資料
公式資料
自動化ROI測定ガイド
本ガイドでは、現在のビジネス状況から収集すべき「ベースとなる指標」から「自動化対象のワークフローの利点」まで、企業が推進すべき「自動化プロジェクトのROI・ビジネス価値」を効果的に計測する方法を詳しく解説。
社内の業務プロセスの自動化を検討する皆様必見です!→ PagerDutyの資料をみる(無料)


テクノロジーの進化にともない、顧客は企業やサービスに対してよりスピーディーな対応を求めるようになりました。その一方で、システム運用プロセスが複雑化しているため、企業では問題解決が遅れがちになり、サービスの停止を招くリスクが増えています。現代において、システムのダウンタイムが引き起こす収益の減少や生産性の低下は、単なるソフトウェアの問題だけに収まりません。組織全体の業務やその後の経営を揺るがしかねない大きな損失につながります。
インシデントの解決に時間がかかるほど、影響は広がり、深刻なものになります。例えば、2023 EMAの調査結果「Automation, AI, and the Rise of ServiceOps」では、自動化やAI、ServiceOpsの台頭にかかわる重大なインシデントやサービス停止により、回答者の19%が深刻な影響(生産性が25%以上低下)を、同47%が重大な影響(生産性が10%〜25%低下)を受けたと答えています。
そのような状況の中、インシデントをより短時間で解決したいと思っても、その手立てに悩む方もいることでしょう。このような問題の解決に役立つのが「PagerDuty Operations Cloud」の機能の一つである「Process Automation」です。Process Automationは、業務を自動化してこれまで専門スタッフしか実行できなかったプロセスを誰でも行なえるようにし、より短時間での問題解決を実現します。自動化を導入すれば、対応者と時間を増やさずともより多くの成果を出せるようになり、インシデント対応のROIを改善できます。本記事では、自動化導入がMTTR(平均修復時間)の短縮にどれほど効果的か、インシデント解決のための自動化にどこから手をつければよいかを、事例をふまえながら解説します。
目次
インシデントが原因で発生した業務の中には急を要するものもありますが、ITと技術チームは毎日大量のアラートに忙殺されています。膨大な量のアラートから、対応者が重要なアラートを識別するのは容易ではありません。しかし、人による分析や意思決定、アクションが重要だからといって、大量のアラートの識別を対応者の手動だけで行なうには、もはや限界があります。なぜなら、対応できる量を増やすために対応者を増員すれば、利益の減少というさらなる問題につながるからです。予期せぬ業務が増えるたびに人件費を投入する方法をとると、ほかの業務が犠牲になり、ROIがマイナスに転じる結果を生むことになりかねません。
また、インシデントの原因追究に欠かせない詳細なコンテキストの収集は、多くの時間とマンパワーを必要とします。PagerDutyの社内データによれば、「インシデント対応時間の85%」が診断前のプロセスに費やされており、インシデント1件につき平均4名以上の対応者が稼働しています。さらに専門スタッフでは「全稼働時間の25%」を専門的で高度な業務ではなく、比較的単純で頻発する作業に費やしているケースが多く見られました。
インシデントの発生・対応を完全になくすことはできません。しかし、インシデント対応での単純作業にエンジニアの多くの時間が取られるのは、非常にもったいない状況といえます。エンジニアが専門的で高度な本来の業務に集中できる環境を整えるためには、不要なエスカレーションによる対応を減らし、より短時間でインシデントを解決できるようにする必要があります。
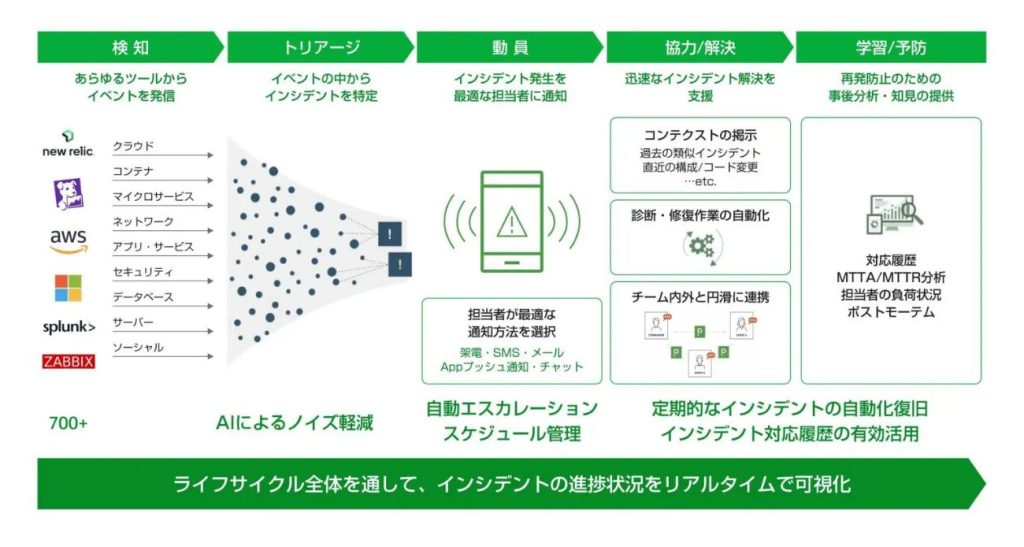
まず、インシデント対応の流れを確認しておきましょう。上の図は、標準化された一般的なインシデント対応の流れです。各項目の内容を簡単に説明します。
監視ツールやオブザーバビリティツールを使ってシステムを監視し、送られるアラートによって異常を検知します。また、コールセンターなどでの問い合わせにより、異常が発覚するケースもあります。
アラートの中から対応が必要なインシデントを特定し、システム運用担当者への通知や自動修復など、適切な一次対応を実施します。
専門スタッフによる対応が必要になった場合、そのシステムの責任者に電話やメールなどで通知します。
専門スタッフのアサイン後、原因の特定と解決に向けたアクションを取ります。場合によっては、追加の情報収集や、過去の類似事象などの調査を実施します。また、インシデントの状況・影響範囲について、関係者やステークホルダーに適切な情報共有を行ないます。
今後のインシデントの未然防止やシステム運用プロセスの改善に向けて「事後検証レポート(ポストモーテム)」を作成したり「システム運用プロセスの見直し」を行なったりします。
インシデント対応については以下の記事でも詳しく解説しています。ぜひ併せてご覧ください。
> 「インシデント対応」とは?〜効率的な体制構築のポイントを解説〜
一連のインシデント対応において、解決までに時間を要する要因の一つに挙げられるのが「エスカレーション」です。エスカレーションとは、対応者での対応が難しいと判断した場合に、より知識・経験を持つ専門家に対応を要請することを指します。これは限られた人的リソースで効率的に対応するための有効な方法といえますが、一方で、一つひとつの対応ではエスカレーションによる引き継ぎの発生は非効率な面もあります。
インシデント対応者が専門スタッフにエスカレーションするのは、「経験値」に差があるからです。対応者だけで問題を解決するには、詳細なコンテキストデータ(診断データ)を集める必要があります。しかし対応者には、自身で解決しようにも、次のような多くの壁が存在します。
このような制約の中で迅速な対応が求められるため、インシデント対応者は十分にパフォーマンスを発揮できないまま、エスカレーションすることになります。その結果、熟練のエンジニアが1つのサービスで多くのインシデントに対応し、同じ診断と修正を手動で繰り返すことになります。そして、本来求められている業務に費やすべき稼働時間のうち、平均25%をエスカレーションの対応に費やしているのです。
そうした状況下にあって、多くの企業や組織がインシデントの解決手順を標準化したいと考えています。この体系的なアプローチを参考にインシデント解決プロセスを簡素化し、どの部分を自動化すれば効率を最大化できるか検討してみましょう。
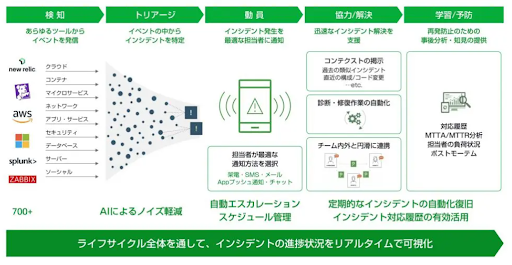
インシデント対応を効率化し、解決までの時間短縮に有効なのが「自動化」です。これまで専門家だけが持っていた知識・ノウハウを自動化ジョブとして対応プロセスにとり入れることで、一次対応者が対応できる範囲を広げ、人的リソースを増やすことなくエスカレーションを抑止できます。併せて、頻発する手作業の自動化により、専門家は本来の高度な業務に集中できるようになります。そして、スムーズで無理のない自動化の導入と実践を強力に支援するのが「PagerDuty Operations Cloud」と、その機能である「Process Automation」です。
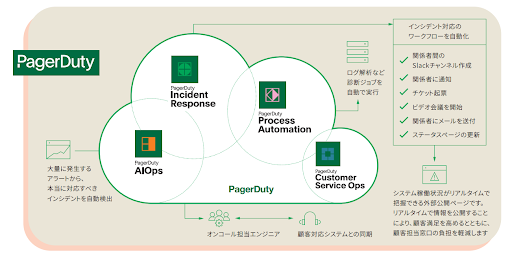
PagerDuty Operations Cloudは、インシデント対応における一連のサイクルをエンドツーエンドで管理するためのプラットフォームです。各種監視ツールと連携してアラートデータを取り込み、ユーザーがノイズの中から重要なシグナルを判別するためのサポートを行ないます。さらにAIOps機能では、対処が必要となる重大な問題である可能性を判断し、重大な問題であればユーザーに通知します。Operations Cloudのインシデント対応機能により、問題解決に適切なチームを適切なタイミングで招集することが可能です。
PagerDuty Operations Cloudの機能の中でも、特にインシデントのトリアージや診断、解決に追加メンバーが必要になった際に活躍するのが「Process Automation」です。Process Automationは、専門知識を自動化ジョブに組み込むことで、対応者がエスカレーションせずトリアージと診断を効果的に行ない、インシデントの多くを解決できるようにする機能です。Process Automationがあれば、経験値の高い技術者の知識を自動化ジョブに組み込み、オンコール対応者に共有できます。この強力な機能は、MTTR(平均修復時間)の短縮に加え、エスカレーション回数とサポートコストの削減に貢献します。技術者は繰り返し発生するインシデント対応に仕事を中断されることなく、安心して画期的なソリューション開発へと集中できるようになります。
PagerDuty Operations Cloudを使用したインシデント対応の自動化は、専門知識を一次対応者に共有してエンドツーエンドでの対応を実現するソリューションともいえます。「インシデントのトリアージ」「診断」「修復」を一次対応者のみで行なえるよう、サポートしてくれるのです。この自動化を導入した際のインシデント対応とはどのようなものなのかを解説します。以下の図は、PagerDuty Operations Cloudを利用して自動化を導入した際のインシデント対応の流れを示しています。
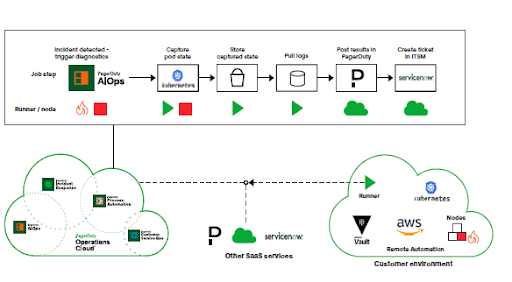
例えば、PagerDutyでインシデントが作成されると、自動的、あるいは対応者がボタンをクリックすることで、自動化ジョブが起動します。あらかじめ用意されたジョブテンプレートとプラグインインテグレーションにより一次対応者には専門知識が提供され、これまでその分野の専門スタッフしか対応できなかった自動化の修正・追加を行なえるようになります。対応に必要となる情報は一次対応者が理解しやすいフォーマットで表示されるため、一次対応者はわかりやすい情報をもとに、サポートを求める際の適任者をより迅速に判断できます。これらの強力な自動化機能を提供するPagerDutyのインシデント解決ソリューションは、Runner経由でファイアウォールの内側またはVPCの内部に配備された基盤と接続されています。Runnerは個々の自動処理を実行し、その結果は暗号化後に中央の自動化環境へと提供されます。
PagerDuty Operations Cloudのインシデント対応ソリューションは、次の5つの機能でインシデント解決の自動化の実現をサポートします。
(1) PagerDuty Automation Actions
ファイアウォールやVPC内の自動タスクと安全に接続し、PagerDutyで発生したインシデントの状況に応じた形で既存の自動タスクをまとめて管理します。PagerDutyの対応者とイベントルールを、本番環境における問題の自動診断と修正に結びつけることで、解決時間の短縮と不必要なエスカレーションの削減を実現します。
(2) PagerDuty Process Automation
Process Automationは、PagerDuty Operations Cloudの自動化機能であるオーケストレーションの一部です。頻出するITプロセスの自動化とオーケストレーションを担い、サービスレベルアグリーメント(SLA)の要件を満たすと同時に、システム運用のコストを削減します。これまでサイロ化していた専門部署をつないだ自動システムにより、人力依存の従来型のチケット管理業務から脱却し、組織の成長とイノベーションを加速させるでしょう。PagerDuty Process Automationが提供する設計環境では、顧客のインフラストラクチャ・サービス・システムに対し、開発者がコマンドやスクリプトの実行、APIの呼び出しといったジョブを定義できます。
(3) プラグインインテグレーション
自動化ワークフローに、APIを安全かつ迅速に統合します。自動化された一般的なインフラストラクチャや、システムへの統合の実現をサポートします。
(4) 事前に定義されたジョブ
あらかじめ定義されたジョブによって、OSとインフラツールに一般的な診断を実施できます。例えば、次のような診断が可能です。
(5) 実装とカスタマイズの迅速な実行
Process Automationの各コンポーネントは、PagerDuty Operations Cloudのその他機能とシームレスに接続されています。これにより、以下のような幅広い対応が可能です。
次の図のように、インシデントライフサイクルの各段階において自動化できる業務が存在します。Process Automationは、これらの各自動化とシームレスに接続し、自動化の設定と実行を可能にします。また「認証」「アクセスコントロール」「ログの監査」「暗号化された接続」といった、セキュリティとコンプライアンスを確保するプラットフォーム機能が、リスク低減とタスク完了の迅速化を実現します。
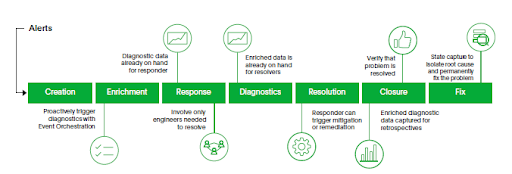
インシデント対応ソリューションであるPagerDutyは、自動化の作成に加え、複数の自動化を接続し、インシデント対応プロセスの強化をサポートします。ここからは、各種機能や、それらの活用による自動化で実現できる内容を紹介します。
✅ アラートノイズの抑制
PagerDuty AIOpsは、同じ問題に関係するアラートを1つにまとめることでノイズを減らし、アラート疲れを軽減します。PagerDuty AIOpsのベータ版利用ユーザーを対象とした調査では、この機能で不必要なインシデントを平均87%削減しています。さらに「Auto-Pause Incident Notifications」を使えば、業務の妨げになるアラートを一時的に抑制できるため、対応者はより重要な業務に集中できます。
PagerDuty AIOpsの詳細な機能と効果については、こちらの記事『PagerDuty新機能「AIOpsアドオン」をリリース 〜AIで革新的なインシデント対応を実現〜』を参照してください。
✅ エンドツーエンドのイベント駆動型自動化
PagerDuty AIOpsでは、グローバルイベントオーケストレーションを介して複数のサービス全体、またはサービスイベントオーケストレーションを使用して単一のサービスに対して、自動診断を起動します。これにより、適切な対応者が呼び出される前に診断スクリプトを実行できます。その結果、チームは人の手を介さずにインシデントの自動解決が可能です。
✅ トリアージの迅速化
PagerDuty AIOpsは、チームが解決に向けた正しいアクションの決定に不可欠な、効率的なトリアージのためのサポートをします。具体的には、過去のイベントで人が行なったインシデント対応データを機械学習し、アクションに必要な情報を導き出します。これにより、情報の分類と優先順位づけを自動化できるため、対応を正しく迅速に行なえます。つまり、適切な専門スタッフの招集と同時に、診断情報をそろえられるようになります。
✅ トリアージの支援
PagerDuty AIOps経由での自動診断が開始されていない場合、一次対応者はAutomation Actionsで自動診断を開始できます。あとは、その診断結果をもとに、対応者が適切な専門スタッフを招集するだけです。PagerDuty CSOpsを利用している場合には、インシデントが顧客に影響を及ぼすレベルの問題だと判断された際に、ZendeskやSalesforce Service Cloudから速やかに診断を実行できます。
✅ 自動修正
Automation Actionsにより、一次対応者はPagerDuty Incident ResponseまたはPagerDuty CSOpsから、速やかに自動修正を行なえます。PagerDuty Automation ActionsとProcess Automationは、既知の問題の自動修正をインシデント対応プロセスの一環として確実に行なえるようにサポートします。
✅ 自動検証
自動修正の実行と、それが正しく機能しているかどうかを検証します。例えば、自動診断の特殊なケースとして自動検証を設定すれば、非常にシンプルなフォーマットの利用が可能です。この場合、レッドまたはオレンジのフラグが立たなければ、問題なしと判断します。自動検証は、金融サービスやヘルスケア分野といった規制のある環境でよく使用され、「ヒューマンエラーの排除」「レポーティング」「必要な変更が反映されたドキュメントの迅速な作成」といったメリットがあります。
✅ 効率的なレトロスペクティブ(振り返り)の実施
インシデント対応における自動化は、解決方法の改善とインシデントの発生防止を実現するために欠かせない、レトロスペクティブにも役立ちます。自動化されたインシデント対応の内容や得られた情報は、漏れなくインシデントレコードとして記録されます。これにより、インシデントに関する一連の情報を簡単に参照でき、すぐにレトロスペクティブを開始できます。つまり、レトロスペクティブの事前準備として手間のかかる情報収集が不要になります。インシデントレコードは、JiraやServiceNowといったチケットシステムからもアクセスが可能です。このように、自動化によって手動の業務を大幅に削減できれば、より多くの時間を原因の追究や重要なフォローアップアクションの検討にかけられるようになります。
✅ 再起動におけるデバッグ状態のキャプチャ
再起動などの緊急措置をとった場合、エンジニアが問題の再現や原因の発見をする際に必要となる非常に重要なエビデンス(ログ、環境変数など)が消去されてしまうことがあります。このような状況を回避するには、サービスの復旧と併せて、エビデンスのキャプチャと保存を瞬時に行なわなければなりません。PagerDuty Operations Cloudのランブックは、問題の検出時に起動してデバッグレベルのエビデンスをキャプチャし、AWS S3などの永続的なストレージサービスに送ります。そのため、再起動に向けて慌ててログ情報を保存したり、再起動後に情報がないために混乱が発生することなく、サービスを既知の解決方法で修復できます。
インシデント対応の自動化は、一気に導入できるものではありません。自動化の優先順位を決める際には、以下のポイントを考慮しましょう。
📝問題発生の頻度
自動化の効果を最大化するには、発生頻度が最も高い問題から自動化を導入します。その中でも特に、エスカレーション頻度の高い問題を優先しましょう。
📝解決手段の成熟度
解決手順がどれほど熟知され、効率的な解決手順が適切にドキュメント化されているかを確認しましょう。適切なドキュメントがあれば、よりスムーズに自動化を導入できます。
📝同じ手順の発生頻度
頻発するインシデントだけでなく、同じサービスで生じる複数の問題に対して同様の診断や修正が行なわれる場合にも、自動化の効果を得やすいでしょう。
📝インシデントの発生期間
インシデントを手作業で解決した際のその労力を忘れてはいけません。特に、解決に長時間を要したインシデントは、自動化の対象として捉えましょう。ただし、自動化の手始めとしてふさわしいのは、ディスク領域不足警告などの単一技術の分野に関するアラート、またはすでにマニュアルとして使えるランブックが存在するアラートです。これらの自動化で経験を積み、処理時間の長いタスクや複数の技術にまたがるタスクの自動化に取り組むのがおすすめです。
📝自動化の導入におけるベストプラクティス
プロジェクトにおいて、自動化を適用できる部分は多く、「ソフトウェアの開発・テスト」から「ランタイム環境の作成」「エラー状態やインシデントへの対応」まで、さまざまです。また、インシデント対応のライフサイクルには、自動化が可能な業務や、人の介在を限りなくゼロにしても同じ結果を出せる頻度の高い業務が多くあります。しかしながら、インシデント対応の自動化を進めるのは容易ではありません。Brinks社のIT自動化マネージャーであるRobert Powers氏は、自動化について次のように述べています。
「自動化を進めることは決して簡単ではありません。日々進めて行く中でさまざまな制約が出てきます。しかし、新たな価値の構築に集中し慎重に進めれば、高い投資対効果が期待できます」
ここでは、自動化にともなう制約や困難を乗り越えるためのポイントを解説します。スクリプトやライブラリーといった形式にかかわらず、自動化の作成と維持にはコストがともないます。だからこそ、人的リソースの面で自動化のメリットが大きい業務は何かを見極めて、自動化を進めることが大切です。自動化を進める際には、次の4つの原則を考慮しましょう。
1. 既存のワークフローを基本にする
自動化は、現在の業務プロセスをサポートするためにあります。自動化のためにワークフローを変更して、現場に混乱を起こすようでは本末転倒です。
2. 結果を出す
エンドユーザーに対しては、ワークフローの自動化により、目に見えるメリットがもたらされるようにしましょう。
3. 一貫性を意識する
コードスタイルや入力パラメーター、ガイドブックの内容を標準化し、統一されたシンプルなユーザーエクスペリエンスを実現しましょう。
4. プロセスをドキュメント化する
自動化プロセスをドキュメント化するために、手法とツールを統一しましょう。自動化への理解が深まり、プロセスの持続性が高まります。
以上の原則に加え、自動化への信頼を高めるための配慮も非常に重要です。いくつか具体例を紹介します。
では、PagerDutyの活用による「インシデント対応の効率化や自動化の事例」を紹介します。
株式会社NTTデータでは、24時間365日稼働しているクレジット・決済事業のインシデント管理にPagerDutyを導入し、自動化を推進しています。これにより、担当者の負荷軽減はもちろん、20~30分かかっていた発報から電話連絡までのプロセスを数秒~数分への短縮に成功しました。
この事例の詳細については、こちらのページ「NTTデータ様事例」をご覧ください。
Tokopediaはインドネシアのテクノロジー企業で、1億人以上の月間アクティブユーザーと900万以上の販売事業者を抱える、東南アジア最大のマーケットプレイス企業の一つです。多くのインシデントで解決までに30分ほどかかるといった、インシデント対応における課題を解決するためにPagerDutyを導入しました。PagerDutyによる自動化の結果、平均修復時間(MTTR)の改善だけでなく、チームの生産性向上により、ソフトウェアの更新が1日あたり10件から300件以上に増加しています。
この事例の詳細については、こちらのページ「Tokopedia様事例」をご覧ください。
自動化を導入する上でよく問題として挙げられるのが「規格に準拠した厳しく保護された環境」での自動化の管理と実行です。このような環境では、あまりにも複雑なセキュリティ条件とプロセス依存関係がゾーンごとに存在するため、結果的に技術者が複数の環境を一つひとつ手動で管理しているというケースがよく見られます。こういった分散したシステムの運用環境における問題の解決に役立つのがPagerDutyの「Runbook Automation」です。
「Runbook Automation」の2つの特長
(1) 異なる環境にまたがる自動ジョブの実行
Runbook AutomationとProcess Automationがあれば、リモート環境での自動化プロセスの承認やオーケストレーションを、あたかもオンプレミスであるかのように実行できます。これにより、多くの環境を1つのジョブ定義に統合することで、自動化できずに手動で認証作業をしなくてはならない「ネットワークのサイロ化」が解消されます。Runbook Automationは、常に検証を行なうゼロトラストの接続性をリモート環境にとり入れ、インフラを自動化されたジョブに集約させることが可能です。
(2) 監査のためのログの記録
Runbook AutomationとProcess Automationは、アクセスコントロールとログの記録を自動化プロセスに組み込み、コンプライアンスを簡素化します。リモート環境に拡張されることで、このすべての機能がコントロールプレーンで一元管理されます。
「Runbook Automation」におけるセキュアな通信
以下の図が示すように、RunnerとAutomation Server間の通信はRunner側から始まり、HTTPSを介して行なわれます。この方法では、RunnerとのコミュニケーションのためにAutomation Server上の影響を受けやすいポート(例:SSH22番ポート)を開く必要がないため、ファイアウォールのセキュリティを強化できます。
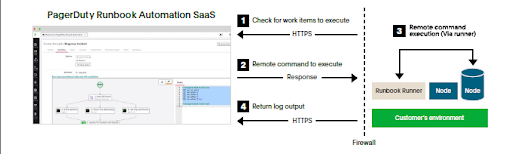
PagerDutyのRunbook Automationは、規格に準拠したセキュアな環境での「自動化の管理」「システム運用の効率化」「最高レベルのセキュリティの維持とシステム監査の両立」に関する問題の解決をサポートします。ランブックの活用について、ChangeHealth社のRusty Boguslavsky氏は次のように述べています。
「サーバーセキュリティの面で、ランブックは既存のコントロールで設定ミスが起こるリスクを劇的に減らしてくれます。つまり、ヒューマンエラーによって新たな脆弱性が増えるリスクが削減されます」
Runbook Automationによるランブックの活用と自動化は、リスク低減と効率化を同時に進められる取り組みといえるでしょう。
一般的に自動化を導入すれば、繰り返し発生する非効率な手作業(トイル)を削減でき、予期せぬ業務に追われたり邪魔されたりせずに、専門的で革新的な業務に取り組む時間を増やせます。その自動化の取り組みの中でも、インシデント対応を自動化するメリットは、決して小さなものではありません。自動化によってインシデント対応の「プロセス全体における一貫性」を確立でき、機械学習をもとに「対応の効果」を高められます。その結果、より短時間でのインシデントの解決が可能になり、サービスの信頼性も向上するでしょう。
本記事の内容を参考に、自社で自動化を導入した際の可能性やメリットを考えてみてください。その際には、自動化に関する機能をトライアルしてみるのがおすすめです。すでにPagerDutyをご利用いただいているお客様は、ログイン後のマイページの「Automation」タブにある「インシデント対応のためのRunbook Automation」からお試し頂くことが可能です。自動化について、さらに詳しく知りたい方は、こちらのホワイトペーパー(英語)をご覧ください。自動化に関する疑問や悩みを解決する際の参考になりますと幸いです。
▼こちらの記事もおすすめ
> システム障害を未然に防ぐ「インシデント管理」とは?
> 「インシデント対応」とは?〜効率的な体制構築のポイントを解説〜
本ガイドでは、現在のビジネス状況から収集すべき「ベースとなる指標」から「自動化対象のワークフローの利点」まで、企業が推進すべき「自動化プロジェクトのROI・ビジネス価値」を効果的に計測する方法を詳しく解説。
社内の業務プロセスの自動化を検討する皆様必見です!→ PagerDutyの資料をみる(無料)

この記事が気になったら




PageDuty公式アカウントをフォロー
 関連ブログ記事
関連ブログ記事


 人気記事
人気記事 検索
検索 タグ
タグ目次












