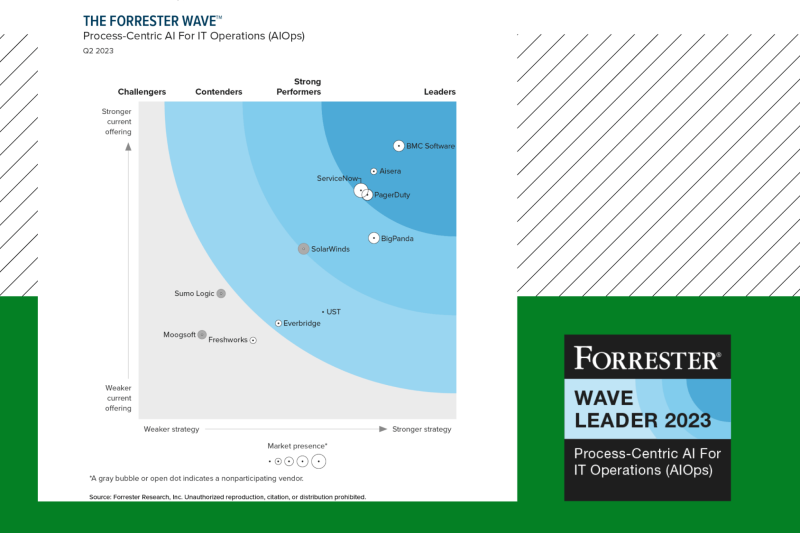
公式資料
公式資料
「デジタルオペレーションの現状」独自調査レポート
エンジニアの燃え尽きを防ぐ秘訣とは?
一段と信頼性の高いシステムを顧客が求めるようになり、勤務時間外や夜間の対応など、技術チームへの要求も増しています。本レポートでは、19,000 社以上、100 万人を超えるユーザーで構成されるPagerDutyプラットフォームから収集したデータを基にしたシステム運用の”今”を解説!→ PagerDutyの資料をみる(無料)


近年、金融機関や通信会社などで多発しているシステム障害。システムが1分停止すると約100万円、24時間で約10億円の損失が起きるともいわれています。現代社会では、クラウド化やデジタルトランスフォーメーションの進展により、私たちの生活がITサービスやITシステムに依存しています。このような状況下でシステムが停止することは、日々の生活に大きな影響を与えることになります。救急車のIoT装置や病院の電子カルテシステムなど、障害によりシステムが停止することで、時には人の命にも関わる可能性があり、社会課題の1つとなっています。
2024年7月19日(金)に発生した、世界規模のシステム障害(インシデント)においても、PagerDutyが分析したところ、インシデント発生は通常と比較して最大150%増加しており、PagerDuty上での復旧作業には通常よりも200%多い人員が投入されたことがわかりました。
システム障害の発生の大きな原因として、「原因究明や回復対応に時間がかかる」ために発生するようにも思えますが、本質的な課題は「システム運用監視体制」が整っていなかったことにあると考えられます。ますますデジタル化が進む中で、システム障害は必ず起きるものであり、ゼロにすることは不可能です。いざというときに適切な「インシデント管理」ができるよう、インシデント対応のための体制や仕組みを構築しておくことが重要です。
本記事では、「インシデント管理を、適切かつ円滑に対応するための環境・体制整備の方法」と「課題を解消するために有効なインシデント管理ツールの活用」について解説します。
目次
ここでいう「インシデント」とは、「システム障害に際して何らかの対応が必要な課題」を指します。「現在ITシステムの障害を引き起こしている課題」または「近いうちにシステム障害につながるような課題」などがその例です。なお近年では、システム障害・インシデント対応対策に数十億円の予算を割いている企業があることは皆さんもご存知かもしれません。
「インシデント管理」とは、ITシステムの運用において、予期せぬサービスの中断や品質低下といったインシデントが発生した場合に、迅速かつ効果的に対応するためのプロセスと体制を指します。インシデント管理の体制を整えておくことで、「インシデントの速やかな解決、システムやサービスを運用する担当者の負担軽減、今後のインシデント抑制」などにつながります。
なお、インシデントと似たような意味合いで利用される「アラート」は、「監視ツールやシステムの通知機能で送信される信号」のことを指します。アラートには「対応が必要」でないものが多く含まれているため、アラートの中の一部がインシデントに分類されます。
システム障害については以下の記事でも詳しく解説しています。ぜひ併せてご覧ください。
> システム障害とは?〜企業が考えるべきリスク対策とインシデント管理〜
インシデント管理と類似した単語として「問題管理」があります。インシデント管理に対して、問題管理とは、ITシステム運用において、インシデントの根本原因を特定し再発防止策を策定するためのプロセスといえます。
| 項目 | インシデント管理 | 問題管理 |
|---|---|---|
| 目的 | インシデントによる被害を最小限に抑え業務への影響を迅速に回復すること | インシデントの根本原因を特定して、再発防止を策定すること |
| 対象 | 予期せぬサービスの中断や品質低下 | インシデントの根本原因となる問題 |
| 具体的な活動 | インシデントの検知・報告 初期対応 原因調査・分析 システム復旧 振り返り・改善案策定 | 問題の識別・分類 問題の原因調査・分析 解決策の策定・実行 再発防止策の策定・実行 問題に関する知識・経験の共有 |
| 時間軸 | 短期的な対応 | 中期的な取り組み |
| 焦点 | 現在の問題解決 | 将来の問題の予防 |
| 担当者 | ヘルプデスク、運用担当者 | 問題管理担当者、システムエンジニア |
システム運用には、運用担当をはじめ、開発担当やその双方を担当するDevOpsエンジニアなど様々な役割の人々が関わっています。ここでは、インシデント管理やインシデント対応にあたって、主にシステムを運用する企業が抱える、よくある課題や悩みを3つ紹介します。
ITシステムを運用するために自社のサーバを利用するオンプレミスや、複数事業者のクラウドシステムを混在させて利用するマルチクラウドなど、利用するサービスそのものが多岐にわたり、年々複雑になる傾向が強まっています。
自社が運用するシステムが複雑になったことで予期せぬ課題が増え、様々な監視ツールから送られてくる大量のアラートに対応しなくてはいけません。監視ツールが異なると、各アラートの詳細や関連情報を調査するためのツールも異なり、インシデントを特定するまでに時間を要したり、大量のアラートに埋もれて緊急対応が必要なインシデントを見落としてしまうこともあります。
テクノロジーの進化と普及により、企業が競争激化や市場のグローバル化にさらされるなか、顧客の期待値も高まり続けています。「24時間365日のサービス提供」や「迅速なレスポンス」が当たり前に求められるなど、高いサービス品質とより短時間での解決・復旧が顧客から求められている一方で、その難易度は上がり続けています。
インシデント対応を外注する場合、インシデント対応を請け負う外注業者は「人数×時間×サーバー台数」等で計算され、コストが下がりにくい傾向にあります。インシデント対応に必要な人員数は把握しづらく、人員不足によりインシデント対応ができなかった、という結果を避けるためには多くの人数をシステム運用のシフトに組み込むことが必要です。
PagerDutyが分析したデータ(https://www.pagerduty.co.jp/resources/state-of-digital-operations-2021/)によると、2019年~2020年の重要インシデント増加率は「19%」になり、「1年間におけるITエンジニアの労働時間が12週間(1日平均で2時間増加)増えた」ともいわれています。
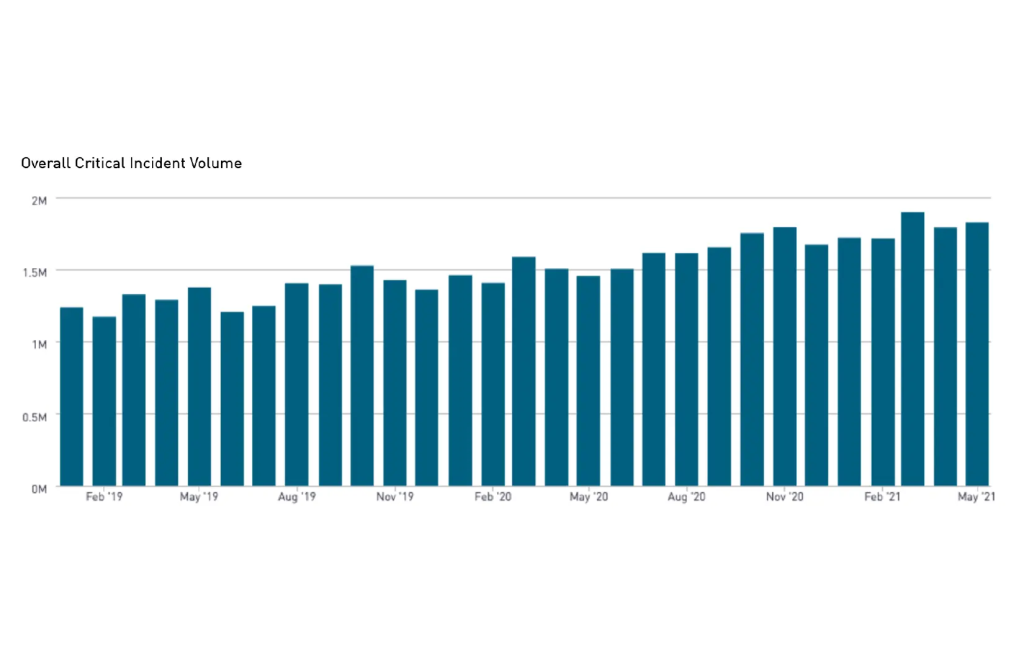
運用プロセスを改善するには、「インシデントの対応履歴」や「MTTA(平均確認時間/インシデントが発生してから、担当者がアサインされるまでの時間)」、「MTTR(平均修復時間/インシデントが発生してから、解決するまでの時間)」等の情報が必要になります。
『定義できないものは、管理できない。管理できないものは、測定できない。測定できないものは、改善できない』とは、改善の祖、W.エドワーズ・デミングの言葉です。インシデント対応のプロセスを改善する際には、自社の運用プロセスを定義した上で測定する仕組みを整備する必要があります。
ここでは具体的にどのようなステップでインシデント管理が行われるのかと、各ステップにおける一般的な課題について説明します。
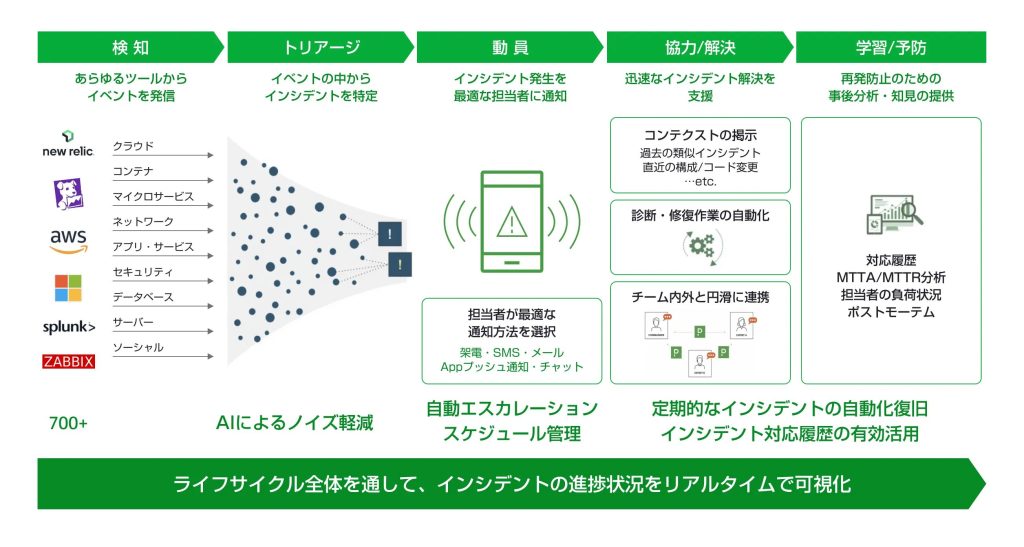
一般的には監視ツールやオブザバビリティツールによってシステムの監視を行い、異常を検知した際にはアラートが送られます。システムが複数あったり、担当部署が違ったりなどの理由で複数の監視ツールを使う場合が多く、各監視ツールで適切にアラートの発報条件を設定しておかないと、必要以上の大量のアラートが送信されてしまいます。仮に監視ツールで適切にアラートを設定していたとしても、システム構成は複雑になっていく傾向があるため、一度システム障害が発生すると、相当数のアラートが同時に送信されることがあります。
受け取ったアラートの中から、インシデント(人の手による対応が必要なもの)を特定し、システム運用担当者への通知や自動修復など、適切な一次対応を実施するステップです。監視センターなどで、このステップを人手で行う場合、オペレーターは手順書(Runbook)を参照して対応を行います。手順書には受け取ったアラートの内容に応じて、「システム担当者に通知するかしないか」「どの担当者に電話で通知するか」等、どのような一次対応を実施すべきかが記載されています。システムが複雑になると、この手順書の内容も複雑になります。大量のアラートに対して人手で対応する場合、対応に時間がかかることはもちろん、時にはミスも発生します。
システム運用担当者による対応が必要になった場合、そのシステムに責任を持つ担当者に通知を行います。緊急の場合は、電話が使われることが多いですが、電話がつながらない(電波が届かない/サイレントモードになっていて気づかない)ケースも多く、オペレーターが人手で電話連絡を行っていると、トリアージの業務に支障が出る場合もあります。
システム運用担当者がインシデントにアサインされれば、次は原因を特定し、解決を行うステップに入ります。この時点でインシデントの原因を特定するための十分な情報がない場合、担当者は自身で情報を集めたり、過去の類似事象などを調査する必要があり、解決までに時間がかかってしまいます。
システムの現在の状況を調査する際は、システムへのアクセス権限が必要になりますが、システムの構成要素の中には(セキュリティ上の理由などで)直接アクセスする権限がないものもあります。このような場合、アクセス権を持つ専門家に一次切り分けなどの対応を依頼する必要があります。
また、インシデントの状況や影響範囲について、社内の関係者(経営者やカスタマーサービス等)にも適切な情報共有が必要になります。情報を共有する仕組みがないと、関係者は顧客や社外の関係者に向けた適切な対応ができず、システム担当者に電話などで状況を問い合わせることになります。問い合わせが多いと、インシデントの調査や復旧を遅らせる原因にもなります。
今後のインシデントの未然防止や運用プロセスの改善に向けて、「事後検討レポート(ポストモーテム)」を作成したり「運用プロセスの見直し」を行うステップです。このような改善を行うには以下のような情報が必要になりますが、これらの情報がなく、問題があることに気づけない・何を改善すべきか分からないといったケースもあります:
インシデントに対してどのように対応すべきか、社内で共通認識がなければ、関係者が協調して対応することができません。どのような役割分担で、それぞれの役割が何をすべきか(すべきでないか)、定義することから始めることをおすすめします。PagerDutyでは自社のインシデント対応プロセスをこちらで公開しています。これからインシデント対応の体制・プロセスを整備しようとしている方は、ぜひご参考にしてください。
大量のアラートに人手で対応しようとすると、時間もかかり、ミスも発生します。受信したアラートをどのように処理すべきかについて、手順書にまとめるのではなく、ルールベースで自動処理する仕組みを使えば、システム担当者がインシデント対応に着手するまでの時間(MTTA:平均確認時間)を数秒に短縮し、誤通知なども削減できます。
PagerDutyでは、ルールベースでアラートを自動処理・担当者への自動通知を行う仕組みに加えて、AIによるノイズ削減機能を活用することができます。関連するアラートを自動集約することで、大量のアラートの中から重要なインシデントが見落とされることを防いだり、自動復旧が予想されるアラートについては、通知を一定時間待つなどの機能があります。
システム担当者がアサインされた後に行う対応についても、自動化する仕組みがあると、インシデント解決までの時間(MTTR: 平均修復時間)を短縮し、インシデントの影響を最小限に抑えることができます。
問題の箇所を特定するためのログ収集などの診断や、復旧のために実施する決められた手順などがあれば、自動化されたジョブとして用意しておき、誰でも簡単にミスなく実行できるよう準備しておくことをおすすめします。繰り返し発生する対応や、複雑で注意や時間を要するプロセスなどは、自動化に向いています。なお既存の対応やプロセスは変わる可能性があるため、現場の担当者自身が自動化のジョブを作成・修正できることが重要です。またPagerDutyでは、AIを使ってインシデント対応で必要になるコンテクスト(解決のヒント)を提示することもできます。これにより、担当者が自身で情報を集める時間と手間を大幅に削減できます:
インシデントの状況や影響範囲を関係者にリアルタイムで共有する仕組みがあると、部門間が協調して対応にあたることができます。例えば、専門家のチームに協力を依頼した場合も、これまでの対応履歴が記録されていれば、すぐに必要な対応を取ることができます。カスタマーサービスでは、顧客からの問い合わせに対して、適切な情報提供ができるようになります。
PagerDutyでは、社内の関係者に状況を知らせる「Status Update機能」の他、各サービスの状況を俯瞰できる「Status Dashboard」を提供しています。エンドユーザー向けの「Status Page」で自社サービスの状況を公開し、エンドユーザーに適切な情報提供ができれば、カスタマーサポートへの問い合わせも減らすことができます。
インシデント対応プロセスを継続的に改善するには、定期的に振り返りを行い、どこに問題があるのか何を改善すべきか検討する必要があります。その際に必要なものが「インシデント対応の記録」です。PagerDutyでは、PagerDuty上で行った操作を自動で記録する仕組みがあります。システム担当者への通知履歴や自動実行したジョブの履歴などです。また、インシデント毎に対応履歴を簡単に記録する仕組みも提供しています。担当者はSlackやモバイルアプリなどから、どのような意思決定や復旧のためのアクションを実施したのか、Notesに残すことができます。これらの対応履歴を参照して、事後検討レポート(ポストモーテム)を作成することもできます。レポート機能では、「各サービスごとのMTTA/MTTR/インシデント数などのKPI」や「各担当者ごとのインシデント対応の負荷状況」も確認することができます。
前項の仕組みを自社で構築しようとすると、費用も時間もかかり、非常に大変です。インシデント管理ツールを導入・利用することで、費用を抑えつつ、すぐにインシデント対応を効率化するというメリットがあります。
次に、インシデント管理ツール選定の際のポイントをいくつかご紹介します。
インシデント管理ツールが障害などで使えなくなると、インシデントに気付くのが遅れたり、解決が大幅に遅れてしまいます。可用性の高いサービスであるか、メンテナンスなどがないか、サービスの異常等を速やかに公開・通知する仕組みがあるかなど、検討する必要があります。
すべてのツールに、自社で求めている機能が備わっているとは限りません。インシデント対応のステップのうち、「動員」の部分だけを提供しているツールもあります。担当者に通知を行うだけでは、インシデント解決時間を短くする効果は非常に限定的になってしまいます。導入前にトライアルを含めた選定を行ない、自社で強化したい業務に合わせた機能が備わっているツールを選んでください。
自社で利用している監視ツールや、アプリケーションと連携できることが重要です。インシデント管理ツールと連携するツールやアプリとしては、監視ツールの他、「JIRAなどのチケット管理ツール」「Slack/MS Teams/Zoomなどのチャット/Web会議ツール」「GitHub/TerraformなどのCI/CDツール」「Salesforce/Zendeskなどのカスタマーサービスツール」等があります。また会社によっては、APIやTerraformで管理できることを重視するかもしれません。
インシデント管理ツールを導入することで、「インシデントの状況の可視化や管理フローの標準化、データの一元管理、自動修復、ナレッジの蓄積」など多くのメリットが享受できます。その結果、企業全体のITインフラの安定性が向上し、業務効率が大幅にアップするだけでなく、システム停止によりお客様に迷惑をかけたり、インシデントにより自社ブランドが毀損したりといった懸念を軽減することが期待できます。
インシデント管理ツールを選ぶ際には、以下のポイントを考慮して、自社に最適なツールを選んでください。
最後になりますが、PagerDutyには上記のポイントが網羅されているほか、全世界20,000以上への導入実績がありますので、企業のインシデント管理に最適なソリューションをご提供することが可能です。インシデント管理ツールをお探しの場合は、PagerDutyの導入をぜひご検討ください。
▼こちらの記事もおすすめ
> インシデント対応とは?事例から読み解く対策方法
> インシデント対応を効率化する「10のチェックポイント」
エンジニアの燃え尽きを防ぐ秘訣とは?
一段と信頼性の高いシステムを顧客が求めるようになり、勤務時間外や夜間の対応など、技術チームへの要求も増しています。本レポートでは、19,000 社以上、100 万人を超えるユーザーで構成されるPagerDutyプラットフォームから収集したデータを基にしたシステム運用の”今”を解説!→ PagerDutyの資料をみる(無料)

この記事が気になったら




PageDuty公式アカウントをフォロー

PagerDuty
Manager, Solutions Consulting
ソリューションズコンサルティング マネージャー
PagerDuty
Manager, Solutions Consulting
ソリューションズコンサルティング マネージャー
ネットワーク機器メーカーにて、インターネット・データセンターのインフラ構築に従事した後、CDNベンダーにて主に動画・ゲーム・電子書籍サービスの拡張性ならびに信頼性向上・セキュリティ対策プロジェクトを推進。2022年よりPagerDuty株式会社にて、インシデント対応の自動化等、デジタルオペレーションのモダン化・成熟度向上を支援している。趣味は自家製スモーカーを使ったベーコン等の燻製作り。
SNS
 関連ブログ記事
関連ブログ記事
 人気記事
人気記事 検索
検索 タグ
タグ目次